NCL Home>
Application examples>
File IO ||
Data files for some examples
Example pages containing:
tips |
resources |
functions/procedures
NCL: Reading CSV (comma-separated values) files
CSV
files are ASCII files whose values are separated by commas or other
separators (semicolons, spaces, etc).
One way to read these files is using a combination of these functions:
You can get away with just using asciiread if you
have a file of all numbers, and no mix of numbers and characters in
any one field.
For examples of reading/writing other types of ASCII files, see:
Sometimes there are multiple CSV files. Rather that looping over many files, it
may be advantageous to create one CSV file contaning all the data.
This is readily accomplished via the unix/linux
cat command:
cat file01.csv file02.cvs .... >! FILE.csv
or
cat file*.csv .... >! FILE.csv
The '>!' are the *nix redirect operator ( > ) and the overwrite operator ( ! ).
csv_1.ncl: Shows how to read a simple
CSV file (
example1.csv) that
contains all integers.
asciiread is used to read the table as strings
first so we can get the number of rows and columns. The
values are then converted to integers using tointeger.
csv_2.ncl: Shows how to read a CSV
file (
example2.csv) that contains
a mix of strings, integers, and fields.
asciiread is used to read the table as strings
and then str_get_field is used to read the
desired fields. There's a mix of integer and float fields,
so tointeger and
tofloat are used to convert from strings to numeric
values.
csv_3.ncl: Shows how to read a CSV
file (
example3.csv) that contains
fields that are all enclosed in double quotes.
asciiread is used to read the table as strings,
str_get_field is used to read the
desired fields, and str_sub_str is used
to remove all the double quotes.
csv_5.ncl:
CSV files with blank cells are very common in "the real world".
The function
str_split_csv makes it easy to correctly read CSV
files with empty fields as missing values.
Note: The
tofloat
returns an _Fillvalue=9.96921e+36. The script manually changes this to
a 'nicer' _FillValue.
The input file, test-with-missing.csv, contains:
168.0 ,157.1
165.5 ,145.8
164.0 ,163.3
169.7 ,169.7
182.8 ,168.3
158.2 ,170.5
155.8 ,
168.8 ,
176.0 ,
211.5 ,200.5
214.5 ,211.6
216.7 ,195.7
219.0 ,193.7
227.5 ,147.5
243.3 ,107.7
146.8 ,72.8
The output would look like:
(0) 168 157.1
(1) 165.5 145.8
(2) 164 163.3
(3) 169.7 169.7
(4) 182.8 168.3
(5) 158.2 170.5
(6) 155.8 -9999
(7) 168.8 -9999
(8) 176 -9999
(9) 211.5 200.5
(10) 214.5 211.6
(11) 216.7 195.7
(12) 219 193.7
(13) 227.5 147.5
(14) 243.3 107.7
(15) 146.8 72.8
csv_6.ncl: Shows how to read a CSV
file
(
479615.NorthDakota.csv)
and extract all strings with a user specified string using
str_match_ic_regex.
Write the selected data to an ascii file via
asciiwrite.
The original code was posted by Karin Meier-Fleischer (DKRZ) in response to an ncl-talk question.
 csv_7.ncl
csv_7.ncl: Read the CSV files
(
479615.NorthDakota.csv)
and
(
479615.latlon.csv)
and extract all strings with a user specified date ('yyyymm') string using
str_match_ic_regex. The 2nd ascii file is read for the latitude
and longitudes of the locations.
Write the selected data to an ascii file via
asciiwrite.
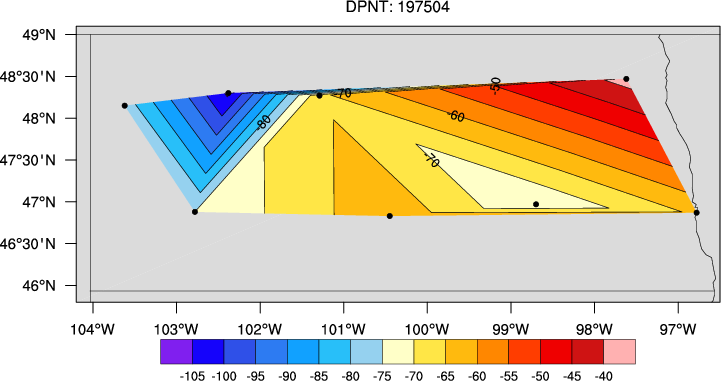
Plot the random stations on a map for yyyymm. This csv file only has 10 stations with data.
Hence, the graphics are a bit crude.
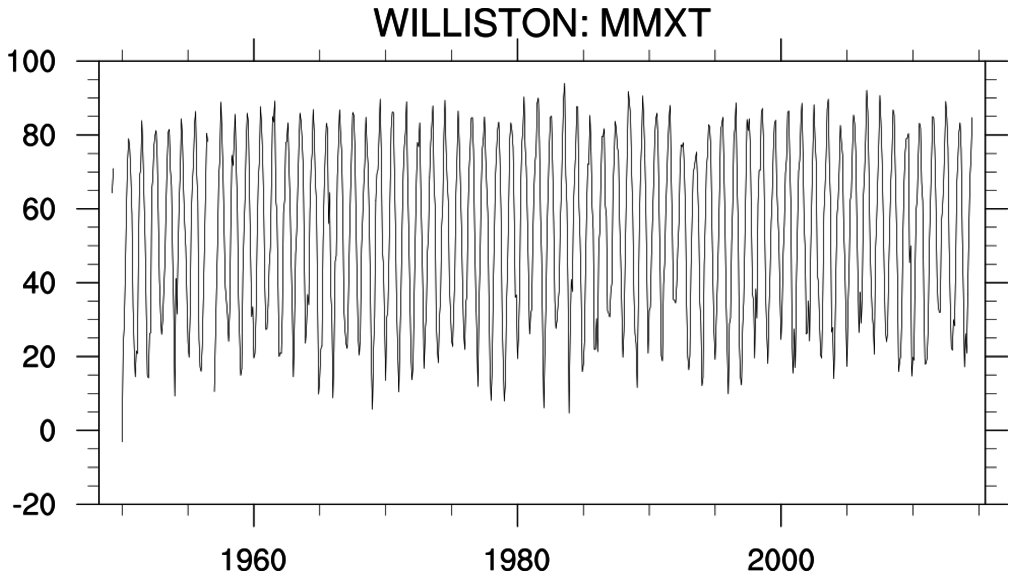
csv_9.ncl: Shows how to read a CSV file
(
tAL.csv) which contains daily data from
14
stations concatenated together. A sample:
"StationID","Year","Month","Day","Julian Day","Precip","Lat","Long"
11084,1950,1,1,2433284.195625,0,31.0581,-87.0547 <=== initial station ID
.....
11084,2011,12,31,2455928.79375,0,31.0581,-87.0547
12813,1950,1,1,2433284.195625,0,30.5467,-87.8808 <=== new station ID
.....
12813,2011,12,31,2455928.79375,0.0508,30.5467,-87.8808
13160,1950,1,1,2433284.195625,0,32.8347,-88.1342 <=== new station ID
.....
readAsciiTable is used to input the data.
NCL's
ind function is used to select data blocks associated with each station.
For demonstration, a simple procedure (could be a function) is used to calculate a
few simple statistcs.
ascii_delim_new.ncl: Shows
how to read a CSV file (
asc5.txt)
that contains header information, and use this information to write
the data to a NetCDF file.
The script is rather lengthy because it does some error checking
of types.
In order to write fields to a netCDF file, the netCDF field
(variable) names cannot contain any tabs or spaces. Hence this script
removes white spaces from the beginning and end of any field names and
converts other white space to underscores ('_'). String or character
values for the fields themselves are not modified.
If you want to use this script for your own purposes, you will need to
modify the script to indicate 1) the input ASCII file name, 2) the
number of fields, 3) the delimiter, 4) the type of each field,
and 5) whether the field contains missing values.
To modify either one for your own data file, first search for the
lines:
;============================================================
; Main code
;============================================================
The lines you need to modify follow shortly:
filename = "asc5.txt" ; ASCII file to read.
nfields = 6 ; # of fields
delimiter = "," ; field delimiter
var_types = new(nfields,string)
var_msg = new(nfields,string)
var_strlens = new(nfields,integer) ; var to hold string lengths,
; just in case.
.
.
.
var_msg = "" ; Default to no missing
var_msg(3) = "-999" ; Corresponds to field #4
var_types = "integer" ; Default to integer
var_types(1:2) = "float" ; Second and third fields
var_types(4) = "character" ; Corresponds to field #5
Change "var_types" to whatever the types of your fields are, and
"var_msg" to what the missing value should be (an empty string
indicates no missing value).
The above code is defaulting all variable types to "integer", and then
changing the 2nd and 3rd fields to type "float" and the fifth field to
type "character" (which in this case is being used as a character
array). The only field that will contain a missing value
is the fourth field.
The allowable variable types are "integer", "float", "double",
"string", or "character". Note that if you read in a variable as a
string, it won't get written to the netCDF file because only character
arrays can be written to a netCDF file.
{kind=link}
{kind=link}
{kind=link}